
Ursprünglich veröffentlicht am 26. September 2024
Verfasst von: Anja Kaup (PR und Marketing Managerin) – anja.kaup@infocient.de
Unternehmen stehen vor der Herausforderung, immer größere Datenmengen effizient zu verwalten und zu nutzen. Besonders SAP-Anwender, die auf die leistungsstarke HANA-Datenbank setzen, suchen nach Wegen, um die Größe ihrer Datenbanken zu optimieren und gleichzeitig die Leistung zu maximieren. Zwei Konzepte, die dabei eine Schlüsselrolle spielen, sind Lifecycle Management und Data Tiering.
In diesem Blogbeitrag erfahren Sie, wie Sie durch intelligentes Datenmanagement nicht nur Kosten sparen, sondern auch die Performance Ihrer SAP HANA-Umgebung signifikant verbessern können. Lesen Sie, wie Lifecycle Management und Data Tiering funktionieren, welche Vorteile sie bieten und wie Sie diese Konzepte in Ihrer eigenen SAP HANA-Umgebung umsetzen können, um das volle Potenzial Ihrer SAP HANA-Datenbank ausschöpfen zu können.
Was ist Data Tiering?
Data Tiering ist eine Strategie zur Klassifizierung der physischen Speicherung von Daten innerhalb eines SAP BW-Systems mit SAP HANA als Grundlage. Ziel ist es, Daten entsprechend ihrer Zugriffsfrequenz optimal im System zu verteilen. Beim Data Tiering in SAP wird das Prinzip der Datenspeicherung in verschiedenen Ebenen oder „Tiers“ angewendet, um die Effizienz und Kosteneffektivität der Datenhaltung zu optimieren
Daten, auf die sehr häufig zugegriffen wird, werden in den Hot-Bereich abgelegt. Daten, auf welche weniger frequent zugegriffen wird, werden im Warm-Bereich abgelegt. Im Cold-Bereich werden Daten ausgelagert, auf welche kaum zugegriffen wird, bis hin zu deren Löschung. Unabhängig der Datenklassifizierung verwaltet die SAP-HANA Datenbank diese und stellt sicher, dass die Daten zur richtigen Zeit zur Verfügung stehen
Die drei Ebenen des Data Tiering
Hot-Tier
- Datenspeicherung physisch in der SAP-HANA Datenbank
- Speicherung von hoch frequentierten Daten
Warm-Tier
- Datenspeicherung im Cache der SAP-HANA Datenbank physische Ablage auf einem nicht In-Memory Speicher (Festplatte oder SSD)
- Speicherung von frequentierten Daten
- Keine Massendatenhaltung
Cold-Tier
- Datenspeicherung physisch außerhalb der SAP-HANA Datenbank auf einem nicht In-Memory Speicher (Festplatte oder SSD) verwaltet durch bspw. Hadoop
- Speicherung von wenig frequentierten Daten
- Massendatenhaltung
Die Konzeption einer HANA Datenbank in Verbindung mit Data Tiering sollte sich an den kritischen Daten ausrichten (im Hot-Tier), die im ständigen Zugriff sind. Die Datenbank muss entsprechend bemessen werden. Daten, welche sich nicht im Hot-Tier befinden, haben langsamere Zugriffszeiten, was sich auf die Reporting-Performance auswirken wird.
Speichermedien für Cold-Daten
Cold-Daten werden üblicherweise nicht auf den aktiv genutzten Festplatten des Primärsystems gespeichert. Stattdessen kommen folgende Speicherlösungen zum Einsatz:
- Separate Festplatten: Langsamere, aber kostengünstigere HDDs können für die Speicherung von Cold-Daten verwendet werden.
- Archiv-Speichersysteme: Spezielle Archivlösungen, die auf langfristige Datenhaltung ausgelegt sind.
- Cloud-Speicher: Kostengünstige Cloud-Storage-Optionen für selten genutzte Daten.
- Optische Medien: In einigen Fällen werden auch optische Speichermedien für die langfristige Archivierung eingesetzt
Technische Konfiguration von Hot-, Warm- und Cold-Tier:
Hot Tier:
- DRAM: Höchste Zugriffsrate, flüchtig
- PMEM: Sehr hohe Zugriffsrate, persistent
Warm Tier:
- Native Storage Extension: Integriert, zweitschnellste Option
- Extension Node: Höchste Performance, parallelisiert
- Dynamic Tiering: Langsamste Option, bis 100TB Speicherung
Cold Tier:
- SAP IQ: Spaltenbasiertes DBMS, für BW-Systeme
- Spark Controller: Integriert in Cold Storage, unterstützt native HANA-Anwendungen
Die Konfiguration und Speicherzuteilung zwischen den Tiers ist individuell anpassbar.
Vorteile von Data Tiering
Die Auslagerung von Cold-Daten auf separate Speicherebenen bietet mehrere Vorteile:
- Kosteneffizienz: Durch die Nutzung günstigerer Speichermedien für selten genutzte Daten werden die Gesamtkosten reduziert.
- Leistungsoptimierung: Die aktiv genutzten Systeme werden entlastet, was zu einer besseren Performance bei häufig benötigten Daten führt.
- Energieeinsparung: Cold-Storage-Lösungen verbrauchen oft weniger Energie, da sie nicht permanent aktiv sein müssen
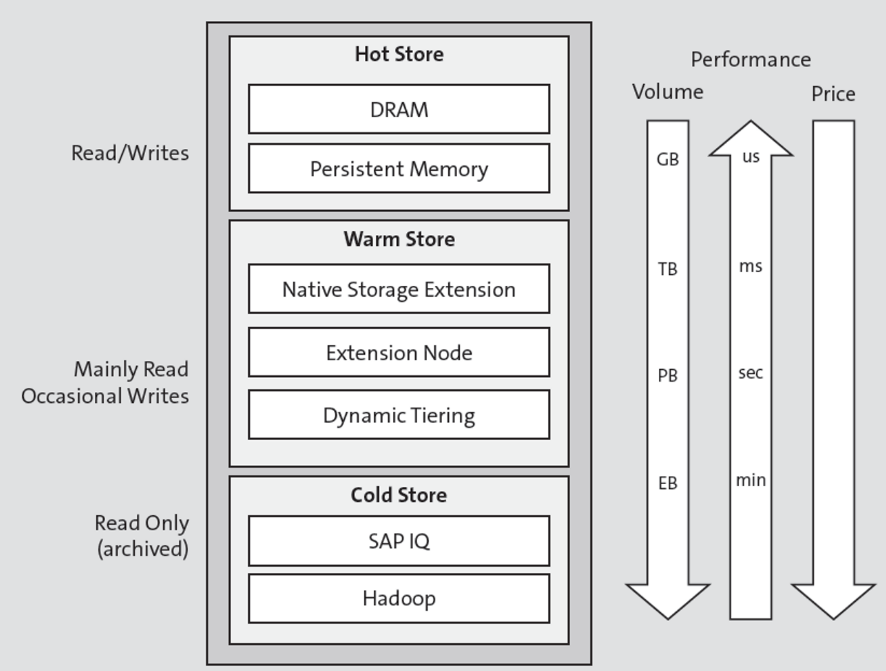
Abb.: Zusammenfassung des Data Tierings. Quelle: https://blog.sap-press.com/options-for-sap-hana-data-tiering
Was ist der Unterschied zwischen Nearline Storage und Data Tiering?
Der Hauptunterschied zwischen Nearline Storage und Data Tiering liegt in ihrem Ansatz und ihrer Anwendung: Nearline Storage ist eine spezifische Speicherklasse, die von Cloud-Anbietern wie Google Cloud angeboten wird:
- Verwendungszweck: Für Daten konzipiert, auf die selten zugegriffen wird, typischerweise einmal pro Monat oder weniger.
- Kosten: Bietet niedrigere Speicherkosten im Vergleich zu Standard-Storage.
- Zugriffszeit: Etwas längere Zugriffszeiten als bei Standard-Storage, aber schneller als bei Cold- oder Archive-Storage.
- Mindestspeicherdauer: Oft mit einer Mindestspeicherdauer verbunden (z.B. 30 Tage bei Google Cloud).
- Anwendungsbeispiele: Datensicherung, Longtail-Multimedia-Inhalte, Datenarchivierung
Data Tiering kann Nearline Storage als eine der Speicherebenen nutzen. In einem Tiering-System könnten beispielsweise aktive Daten auf SSDs oder HDDs verbleiben oder weniger häufig genutzte Daten in Nearline Storage verschoben werden. Sehr selten genutzte Daten können in noch günstigere Speicherklassen wie Coldline oder Archive Storage migriert werden.
Durch die Kombination von Data Tiering und verschiedenen Speicherklassen wie Nearline Storage können Sie Ihre Speicherkosten optimieren und gleichzeitig die Leistung für häufig genutzte Daten aufrechterhalten.
Was ist Information Lifecycle Management?
Lifecycle Management beschreibt, wie sich die Klassifizierung von Daten im Laufe der Zeit verändert. Neue, häufig genutzte Daten beginnen als „Hot“ und werden mit abnehmender Nutzung zu „Warm“ und schließlich zu „Cold“ Daten.
Dieser Prozess empfiehlt sich, wenn das Speichern von Daten innerhalb der SAP-HANA sehr kostenintensiv wird. In diesem Fall lohn es sich, lediglich die Daten In-Memory zu halten, welche für das hoch frequentierte Reporting unerlässlich sind.
Ein typisches Beispiel:
- Aktuelle Jahresdaten: Hot (häufiger Zugriff für Planung und Reporting)
- Vorjahresdaten: Warm (gelegentlicher Zugriff für Vergleichsanalysen)
- Ältere Daten: Cold (seltener Zugriff, ausgelagert aus SAP HANA)
Darüber hinaus lassen sich Daten über die Aktualität in „Hot, Warm, Cold“ klassifizieren. Bei der Betrachtung eines persistierenden Datenmodells entlang des LSA++ Modells werden verschiedene Schichten benötigt.
Reporting
- HOT-Data mit sehr regelmäßigen Zugriffen für Reporting und/oder Planung
- Speicherung in DataMart’s oder Standard aDSO’s (Architected Data Mart Layer, EDW Layer)
Harmonization / Acquisition
- Warm-Data mit regelmäßigem Datenzugriffen, eine Speicherung in der SAP-HANA ist nicht zwingend notwendig
- Speicherung in Persistierenden aDSO’s im Corporate Memory oder im Open Operational DataStore Layer
Archiving
- Cold-Data mit seltenen Datenzugriffen, welche nicht in der SAP-HANA gespeichert werden müssen
- Speicherung außerhalb der SAP-HANA Datenbank, Anbindung z. B. mittels Nearline Storage
Warum sind diese Konzepte wichtig?
- Kosteneffizienz: In-Memory-Speicher in SAP HANA ist leistungsstark, aber kostspielig. Durch intelligentes Data Tiering optimieren Sie Ihre Speichernutzung und reduzieren Kosten.
- Performance: Indem Sie nur die wichtigsten Daten im Hot Tier halten, gewährleisten Sie optimale Zugriffszeiten für kritische Geschäftsprozesse.
- Skalierbarkeit: Mit wachsendem Datenvolumen ermöglicht Ihnen Data Tiering eine flexible Anpassung Ihrer Speicherstrategie.
Praktische Umsetzung
Bei der Implementierung von Data Tiering und Lifecycle Management sollten Sie folgende Punkte beachten:
- Analysieren Sie Ihre Datenzugriffsmuster, um eine effektive Klassifizierung vorzunehmen.
- Konfigurieren Sie Ihre SAP HANA-Datenbank entsprechend Ihrer Hot-Data-Anforderungen.
- Implementieren Sie automatisierte Prozesse zur regelmäßigen Überprüfung und Anpassung der Datenklassifizierung.
- Nutzen Sie die verschiedenen technischen Optionen für Warm- und Cold-Tier-Speicherung, je nach Ihren spezifischen Anforderungen.
Fazit
Durch den Einsatz von Data Tiering und Lifecycle Management können Sie die Leistungsfähigkeit Ihrer SAP HANA-Datenbank optimal ausnutzen, Kosten senken und gleichzeitig die Flexibilität Ihres Systems erhöhen. Als erfahrener SAP-Partner unterstützen wir Sie gerne bei der Implementierung dieser Konzepte in Ihrem Unternehmen und der Optimierung Ihrer Datenbank.
Möchten Sie mehr darüber erfahren, wie Sie Ihre SAP HANA-Umgebung optimieren können? Kontaktieren Sie uns für eine individuelle Beratung!
- schicken Sie uns eine E-Mail oder
- fragen Sie Dr. Armin Elbert telefonisch: +49 621 596 838-50


